
Input video
|

→ Crow
|

→ Pigeon
|

→ Chicken on the ice
|

→ Stork on the snow
|

→ Duck on the mud
|

→ Eagle on the mud
|

→ Owl on the grass
|

→ Flamingo on the grass
|
|---|

Input video
|

→ Astronaut
|

→ Firefighter
|

→ Oil painting
|
→ Pixel art
|

→ Watercolor painting
|
|---|
Abstract
Text-driven diffusion-based video editing presents a unique challenge not encountered in image editing literature: establishing real-world motion. Unlike existing video editing approaches, here we focus on score distillation sampling to circumvent the standard reverse diffusion process and initiate optimization from videos that already exhibit natural motion. Our analysis reveals that while video score distillation can effectively introduce new content indicated by target text, it can also cause significant structure and motion deviation. To counteract this, we propose to match space-time self-similarities of the original video and the edited video during the score distillation. Thanks to the use of score distillation, our approach is model-agnostic, which can be applied for both cascaded and non-cascaded video diffusion frameworks. Through extensive comparisons with leading methods, our approach demonstrates its superiority in altering appearances while accurately preserving the original structure and motion.
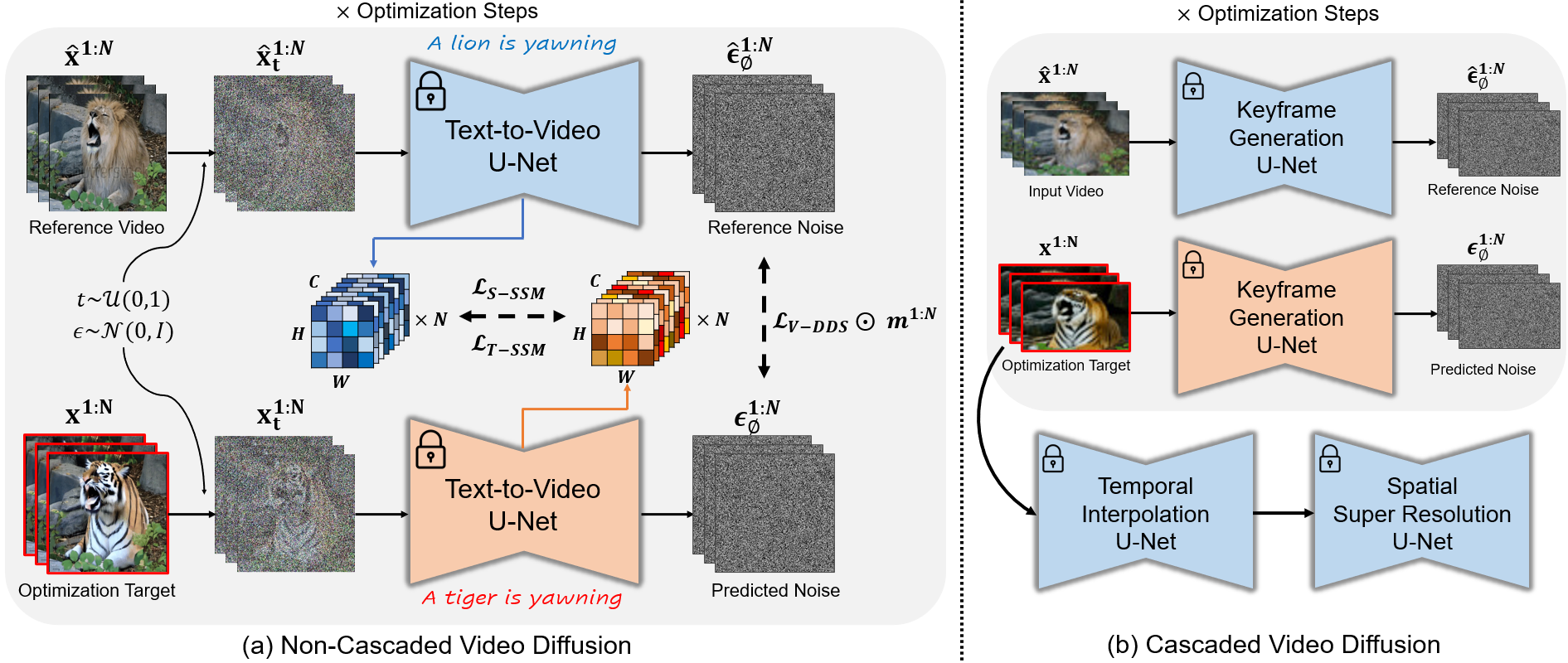
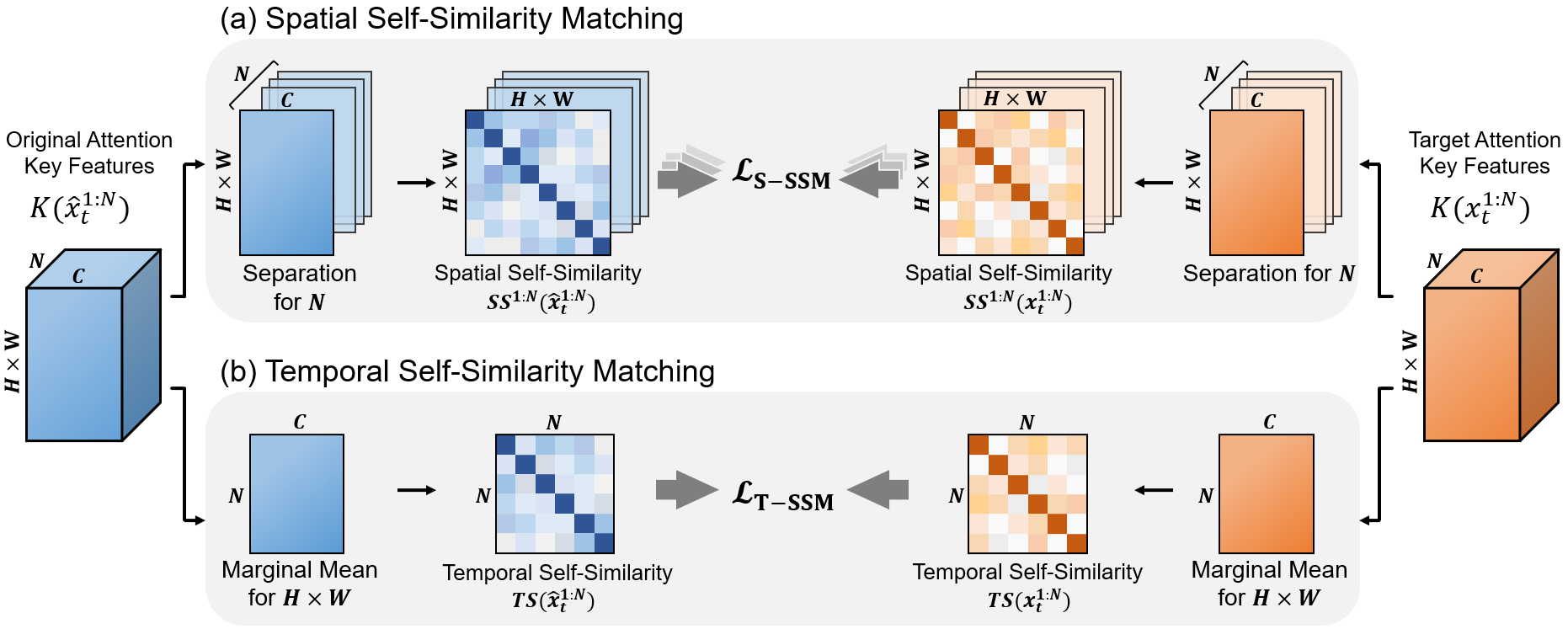
DreamMotion with Zeroscope T2V

Input video
|

→ Taxi,
under sunset |

→ School bus,
under aurora |

→ Truck,
under fireworks |

→ Vintage car,
under dark clouds |
|---|

Input video
|

→ Convertible
|

→ Police car
|

→ Porsche
|

→ Lamborghini, on sunset
|
|---|

Input video
|

→ Fox
|

→ Horse
|

→ Tiger
|

→ Goat
|
|---|

Input video
|

Man → Child
Dog → Corgi |

Man → Child
Dog → Pig |

Man → Woman
Dog → Goat |

Man → Woman
Dog → Tiger |
|---|

Input video
|

→ Chicken
|

→ Duck
|

→ Eagle
|

→ Flamingo
|

→ Pigeon
|
|---|
DreamMotion with Show-1 Cascaded T2V

Input video
|

→ Shark, under water
|

→ Spaceship, in space
|
|---|

Input video
|

→ Boat, on the sea
|

→ Military aircraft
|
|---|

Input video
|

→ Buses
|

→ Locomotives
|
|---|

Input video
|

→ Pink swan
|

Input video
|

→ Lamborghinis
|
|---|
Comparison to Baselines
A dog is jumping into a river. → A horse is jumping into a river.
|
Input video
|
DreamMotion w/ Zeroscope
|

Tune-A-Video
|

ControlVideo
|
|---|---|---|---|

Control-A-Video
|

Gen-1
|

TokenFlow
|
A seagull is walking. → A duck is walking on the mud.
|
Input video
|
DreamMotion w/ Zeroscope
|

Tune-A-Video
|

ControlVideo
|
|---|---|---|---|

Control-A-Video
|

Gen-1
|

TokenFlow
|
A car is driving on the road. → A lamborghini is walking is driving on the road, on sunset.
|
Input video
|
DreamMotion w/ Zeroscope
|

Tune-A-Video
|

ControlVideo
|
|---|---|---|---|

Control-A-Video
|

Gen-1
|

TokenFlow
|
A man is skateboarding. → A firefighter is skateboarding.
|
Input video
|
DreamMotion w/ Show-1
|

DDIM inversion + Word swap
|

VMC
|
|---|
Cars are running on the bridge. → Buses are running on the bridge.
|
Input video
|
DreamMotion w/ Show-1
|

DDIM inversion + Word swap
|

VMC
|
|---|
Visualizing Optimization Progress
| Optimize: Car → School bus, under aurora | |||

|

|

|

|
|---|---|---|---|
| Optimize: Dog → Fox | |||

|

|

|

|
|---|---|---|---|
| Optimize: Man → Astronaut | |||

|

|

|

|
|---|---|---|---|
Additional Comparisons with Video-P2P and DMT
A seagull is walking. → A flamingo is walking on the grass.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
A car is driving on the road. → A lamborghini is walking is driving on the road, on sunset.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
A man is walking a dog on the road. → A child is walking a pig on the road.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
A man is walking a dog on the road. → A woman is walking a tiger on the road.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
a car is driving on the road under the sky. → A school bus is driving on the road under aurora.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
a car is driving on the road under the sky. → A truck is driving on the road under fireworks.
|
Input video
|
DreamMotion w/ Zeroscope
|

Video-P2P
|

DMT
|
|---|
References
• Sterling, Spencer. Zeroscope. https://huggingface.co/cerspense/zeroscope_v2_576w (2023).
• Zhang, David Junhao, et al. "Show-1: Marrying pixel and latent diffusion models for text-to-video generation." arXiv 2023.
• Wu, Jay Zhangjie, et al. "Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation." ICCV 2023.
• Zhang, Yabo, et al. "Controlvideo: Training-free controllable text-to-video generation." arXiv 2023.
• Chen, Weifeng, et al. "Control-a-video: Controllable text-to-video generation with diffusion models." arXiv 2023.
• Esser, Patrick, et al. "Structure and content-guided video synthesis with diffusion models." ICCV 2023.
• Geyer, Michal, et al. "Tokenflow: Consistent diffusion features for consistent video editing." ICLR 2024.
• Jeong, Hyeonho, et al. "Vmc: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models." CVPR 2024.
• Yatim, Danah, et al. "Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer." CVPR 2024.
• Liu, Shaoteng, et al. "Video-p2p: Video editing with cross-attention control." CVPR 2024.